Learning and Estimation
One of the key problems in science and engineering is to provide a quantitative description of the systems under investigation leveraging collected noisy data. Such a description may be intended as a full mathematical model, or as a mechanism to return predictions corresponding to new, unseen, inputs. Our research in learning is targeted both to static and dynamic systems, aiming for strategies that trade off accuracy and computational speed to be used, e.g., in the context of (adaptive) control. In this context, we are also interested in providing algorithms to perform state estimation of dynamical systems from noisy data.
Nonlinear State Estimation
The availability of accurate state estimates is essential for high performance control of safety critical systems. We investigate the design of advanced nonlinear state estimation algorithms for such systems. Our focus is on algorithms with stability properties and quantification of the uncertainty in the state estimate, as well as the use of learning algorithms to adapt the estimators online to unknown system models, or to integrate visual measurement units.
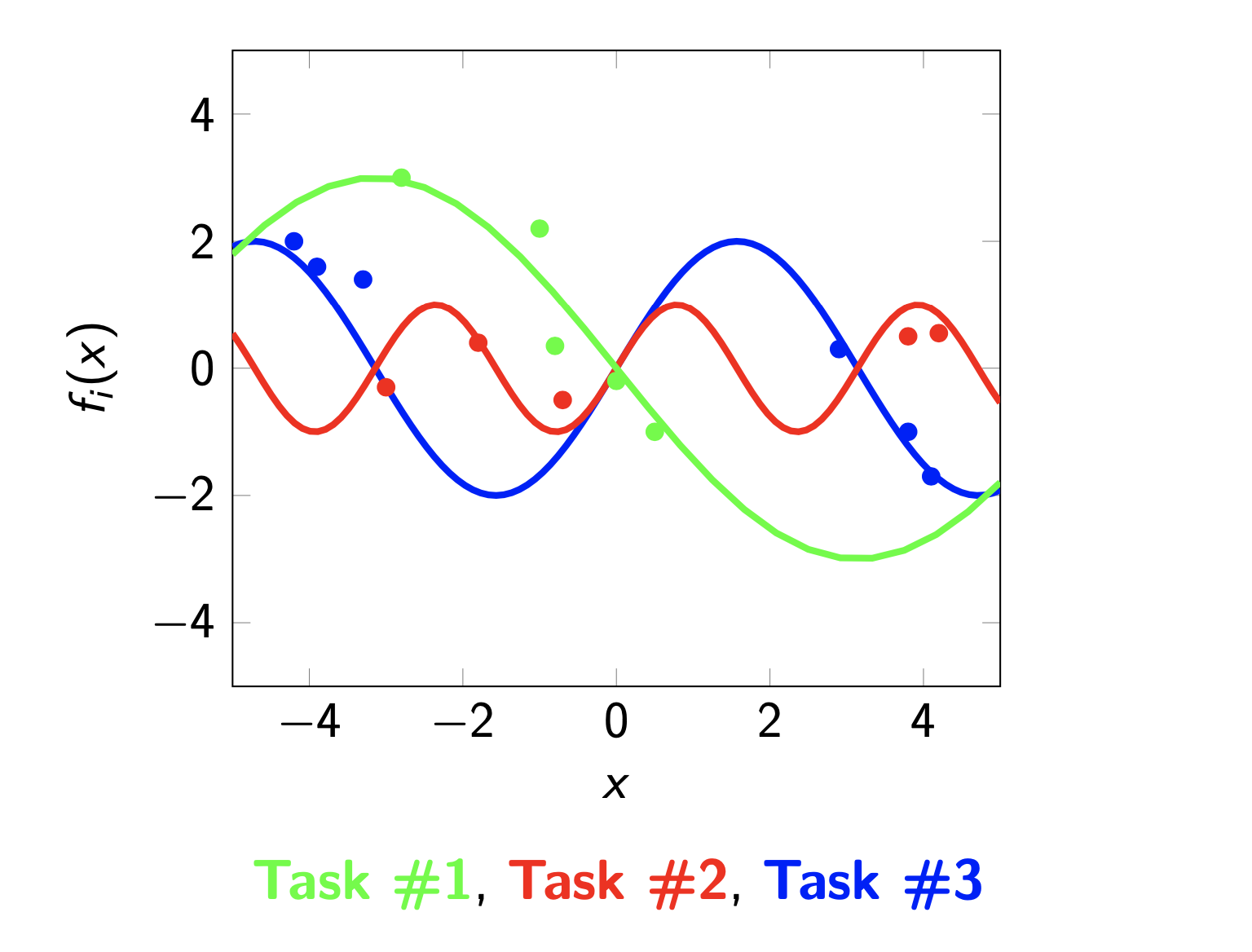
Multi-task/Meta-Learning for Dynamic Systems
In many applications, data are collected from different, but related, operating conditions. Instead of working on the single data-sets, it is usually beneficial to leverage the underlying relatedness to improve the estimation performance. The goal of this project is to develop methods for such a set-up in view of dynamical systems identification.
Active Learning for Model-based Control
Offline system or reward identification becomes increasingly challenging and time-consuming for complex systems and environments. This problem can be addressed by learning-based control techniques, leading to the well-known exploration-exploitation trade-off. This project aims at providing approximate solutions that offer computationally feasible optimization-based formulations for balancing exploration and exploitation in the context of model-based control, both in the case of unknown dynamics, and in the case of unknown cost functions.
Dynamic Regret Minimization
Dynamic regret is defined as the difference between the incurred cost of a proposed controller and the cost a non-causal controller, with access to all future disturbances, could have achieved. It can be seen as an alternative control objective to H2- and H∞-control. The dynamic regret optimal controller can be exactly computed and can outperform these classical approaches as it adapts to the measured disturbances. The aim of this research is to synthesize dynamic regret minimizing controllers for systems which are safety-critical and have unknown dynamics.
